우리가 어떤 문제에 직면했을 때 해당 문제와 비슷한 결과들이 있다면 훨씬 수월하고 빠르게 문제를 해결해 나갈 수 있을 겁니다.
이번에는 바로 그 개념인 *Transfer learning과 **fine tuning에 대한 내용을 다뤄볼까 합니다.
먼저 예를들면, 우리는 개와 고양이 이미지 데이터셋을 분류하고 싶습니다. 여기서 우리는 이미 개와 고양이 같은 수 많은 동물들의 class를 분류한 모델들을 알고있습니다. 가령 vgg net, google net, resnet 같은 모델들이 있죠.
이렇게 이미 학습된 pretrained model을 불러와서 pretrained model의 파라미터를 적용하는 transfer learning을 합니다.
이 과정에서 현재는 개와 고양이 이진 분류만 하면 되므로 불러온 모델이 현재 task에 좀 더 집중하도록 fine tuning을 해주는 것입니다. 새로운 데이터로 다시 한 번 가중치를 미세 조정 해주는 것이죠.
여기서 이미지넷에 쓰인 모델을 쓰기 위해서는 이미지넷은 class 1,000개를 분류하는 모델이었으므로 fc layer를 이진분류로 바꿔주는 등의 조작이 필요합니다.
※ transfer learning ? fine tuning ?
혼동될 수 있는 개념인 것 같습니다. 거의 transfer learning = finetuning으로 봐도 무방합니다. imagenet이라는 큰 데이터로 pretrain된 backbone을 이용해 feature map을 뽑아내고, 아래 4가지 처럼 fine tuning을 자신의 데이터셋에 맞게 fc layer만 다시 설계하는 겁니다!
가령 object detection이나 segmentation의 문제에서 resnet의 CNN을 classification이 아닌 feature extraction으로만 쓰는 경우는 "transfer learning으로 가중치를 가져왔다." 혹은 "resnet의 CNN을 backbone으로만 썼다" 라고 합니다.
하지만 task가 바뀐 이런 경우에도 자신의 데이터에 더욱 fit하게 backbone을 다시 학습 시킨다면, finetuning이라고 합니다.
예시를 개 - 고양이 분류로 들었지만, 항상 다양한 문제에 직면할 수 있습니다.
따라서 fine tuning을 할 때에는 중요한 점이 있습니다.
바로 현재 task의 데이터양과 pretrained model과의 dataset, task 관련 유사정도입니다.
아래 4가지로 분류할 수 있습니다.
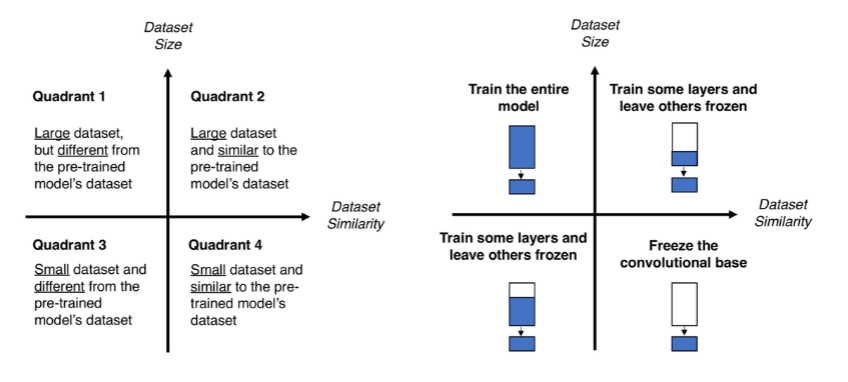
1. 현재 해결하려는 task의 dataset size가 충분하지만, 선행 학습 되었던 데이터셋과 많이 다를 경우
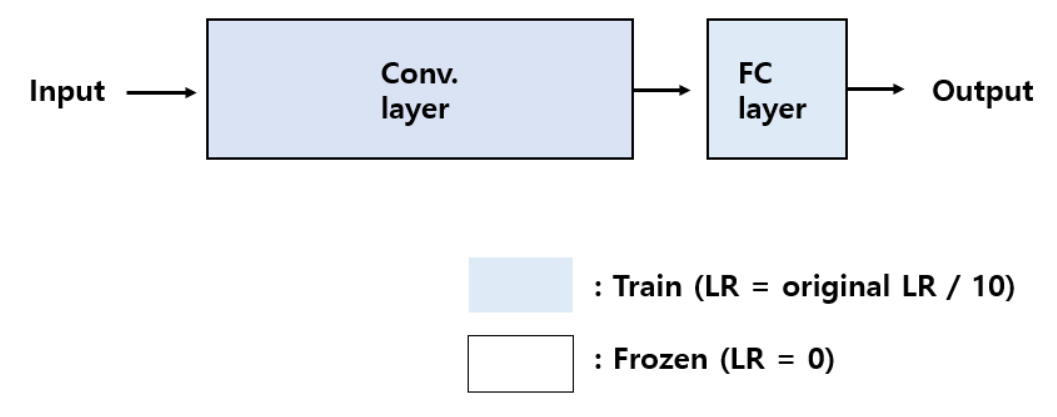
보통 base model을 ***Backbone이라고 하며, Conv layer를 거쳐서 나온 특성들을 ****Bottleneck feature라고 합니다.
현재 데이터셋은 학습할 만큼 충분하고, 선행 학습된 데이터와는 차이가 있는 경우이므로 네트웍 전부를 다시 학습해주어 좋은 퍼포먼스를 기대합니다.
lr을 크게 잡으면 pretrained model의 가중치를 훼손시킬 수 있기에 보통 1/10정도로 세팅해줍니다.
fine tuning에서는 optimizer도 이전 가중치를 훼손시키지 않는 RMSProp보다는 SGD와 같이 안정적인 학습 속도를 유지하는 optimizer를 사용하는 것이 바람직합니다.
2. 현재 해결하려는 task의 dataset size가 충분하지만, 선행 학습 되었던 데이터셋과 유사할 경우
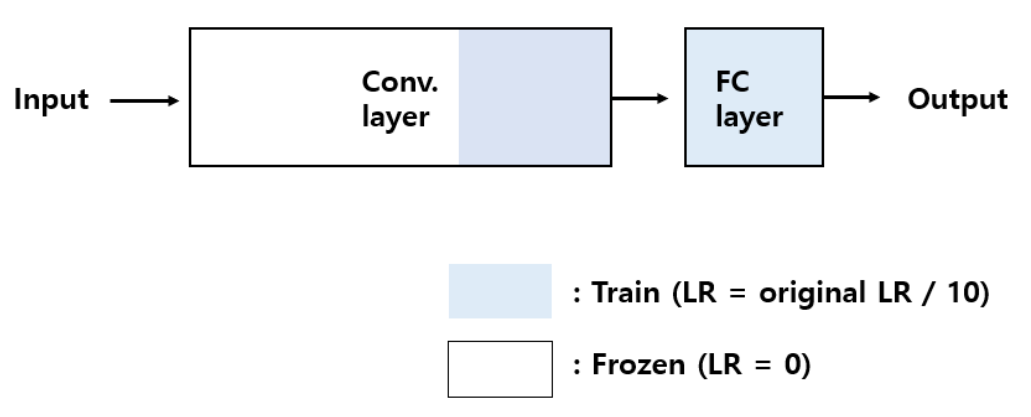
Conv layer는 초반 input layer와 가까운 계층일수록 선이나 색과 같은 일반적인 특징을 학습합니다.
ouput layer와 가까운 계층일수록 좀 더 class와 관련된 세세한 특징들을 학습하죠.
학습할 dataset size는 충분하지만, 선행 학습된 데이터셋과는 유사한 경우에는 굳이 시간을 써가면서 모든 Conv layer를 학습할 필요는 없습니다.
Conv layer 초기 계층은 lr을 0으로 걸어 학습을 진행하지 않고, 현재 task에 조금 더 fit한 특징을 유도하도록 Conv layer 후기 계층 일부와 fc layer만 fine tuning해줍니다.
3. 현재 해결하려는 task의 dataset size가 작고, 선행 학습 되었던 데이터셋과 많이 다를 경우

이 경우가 가장 문제입니다. dataset size도 작은데, 선행 학습 되었던 데이터와도 차이가 있는 경우죠.
데이터가 너무 작아서 오버피팅을 조심해야하기 때문에 1번의 경우처럼 ConV layer 전부를 다시 학습 시킬 수도 없으므로 위와 같이 fine tuning 해줍니다.
정말 어려운 문제인데, 이 경우는 image augmentation을 좀 더 신경쓰는게 최선일 것 같습니다.
4. 현재 해결하려는 task의 dataset size가 작고, 선행 학습 되었던 데이터셋과 비슷할 경우
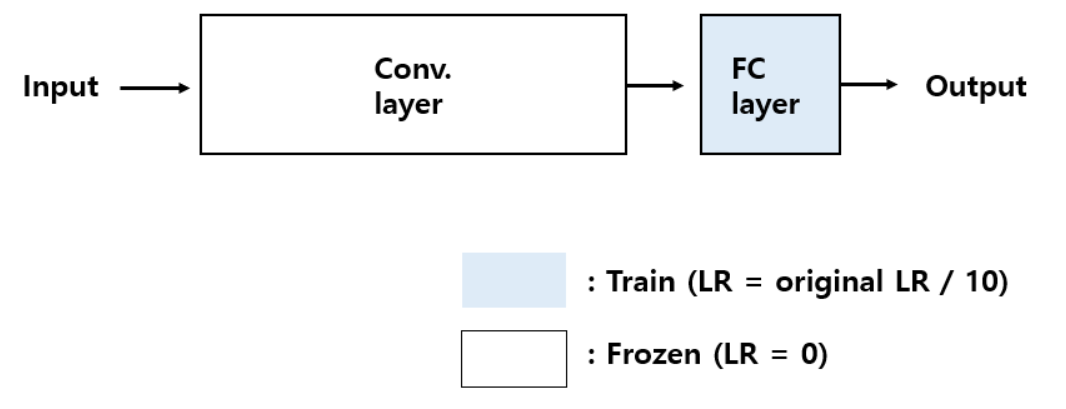
데이터셋이 작을 때는 항상 오버피팅의 가능성을 견제해야 하므로 이런 경우에는 Conv layer를 동결시키고 bottleneck feature를 뽑아서 FC layer만 학습시킵니다.
사실 이 경우에는 피쳐를 추출해내는 layer의 파라미터를 아예 학습시키지 않으므로 fine tuning이 아니라고도 하는 시각이 있습니다.
마지막으로 전체적으로 굉장히 중요한 부분이 있습니다.
Conv layer 전체나 일부를 동결 시키고, 현재 task를 해결하기 위해 새로운 FC layer를 학습시킨다고 무작정 새로운 FC layer를 붙여버리면 안됩니다. 모든 layer는 꼭 1번 이상은 학습이 완료된 상태여야됩니다.
무작위로 가중치가 부여된 새로운 FC layer에서 자칫 큰 가중치가 학습될 위험이 있습니다.
fine tuning은 이미 학습된 안정적인 가중치들이기 때문에 이를 망치면 안됩니다. 이렇게 되면 Conv layer의 방대한 데이터를 학습해서 얻어진 기존 네트워크의 가중치를 너무 크게 바꿔서 핵심 학습 내용을 잃게 될 수도 있는 것이죠.
그렇다면 어떻게 하는 것이 좋을까요?
제가 참고한 자료입니다.
keraskorea.github.io/posts/2018-10-24-little_data_powerful_model/
해당 링크에서는 이 글의 3에 해당하는 문제 해결을 위해 vgg16으로 fine tuning하는 과정이며, bottleneck feature들로 미리 FC layer를 학습하여 가중치를 저장해둔 뒤 3의 fine tuning에 미리 학습시켜둔 FC layer를 붙여 학습을 진행합니다.
모든 layer가 1번 이상 학습이 완료된 상태를 만든 것입니다.
그 과정의 설명과 코드가 매우 자세히 나와있습니다.
마지막으로 놓칠 수 있는 fine tuning의 포인트를 짚자면,
1. learning rate를 매우 작게 설정한다. ( 통상 1/10 수준 )
2. 보통 안정성 있는 SGD같은 optimizer를 이용한다.
3. bottleneck feature만 따로 저장하여, FC layer만을 학습시키면 많은 학습 시간을 절약할 수 있다.(데이터 augmentation이 필요하지 않을 정도로 학습 데이터 셋의 크기가 크다면)
4. 모든 layer는 꼭 1번 이상 학습이 완료된 상태여야한다.
위 글을 토대로 직접 수집한 데이터들로 fine tuning을 적용한 실습 포스팅입니다!
이 글을 정독하신 분이라면 흥미로운 결과이니 꼭 읽어보시길 권장드립니다 :)
https://inhovation97.tistory.com/41
6. ResNet50 Transfer learning & fine tuning 적용하기(이미지 수집부터 분류 모델까지)
이 포스팅은 아래 흐름대로 진행되는 포스팅입니다. 데이터 수집 - 전처리 - 모델링 - 성능 개선 이 포스팅에서 저는 직접 이미지를 크롤링하여 수집하고(링크1), 수집한 이미지를 정리하고(
inhovation97.tistory.com
다음 포스팅은 1, 2에 관련한 저의 실험 결과입니다.
이 글을 정독하신 분이라면 흥미로운 결과이니 읽어보시길 권장드립니다 :)
Learning rate & batch size best 조합 찾기 (feat.논문리뷰와 실험결과)
이번 포스팅은 저의 지난 포스팅의 배경 지식이 요구되므로 읽고 오시기를 추천드립니다 :) 저는 모델링 경험이 엄청 많지는 않기 때문에 고수분들에게는 해당 포스팅이 당연한 인사이트일 수
inhovation97.tistory.com
'Deep Learning 개념정리' 카테고리의 다른 글
| Learning rate & batch size best 조합 찾기 (feat.논문리뷰와 실험결과) (21) | 2021.03.31 |
|---|---|
| [소프트맥스 회귀] softmax와 cross entropy 이해하기 (0) | 2021.02.09 |
| [로지스틱 회귀] 시그모이드 함수와 MSE, Cross entropy (0) | 2021.02.09 |
| CNN( Convolutional Neural Network)이해하기 (0) | 2020.08.13 |




댓글