이 포스팅은 아래 흐름대로 진행되는 포스팅입니다.
데이터 수집 - 전처리 - 모델링 - 성능 개선
이번엔 이전 포스팅에서 크롤링을 했던 이미지들을 정리하기위한 작업입니다.
https://inhovation97.tistory.com/33 << 이전 포스팅 [1. 파이썬 이미지 데이터 크롤링하기]
이미지들을 정리하는 작업이기 때문에 파일 이름 변경, 파일 경로 변경, 파일 정렬, 파일 복사 등등을 코딩을 통해 효율적으로 정리합니다.
포스팅 순서
1. 이미지 넘버링 (파일 이름 변경)
2. 이미지 시각화하기
3. 이미지 랜덤 추출하여 train/test split (파일 복사)
4. train/test의 이미지들을 다시 넘버링
저번 포스팅에서 크롤링했던 이미지는 일일이 정제해줬습니다.
train/test 셋을 준비하기 위해서는 이미지 파일들을 잘 정리해서 저장해야하기 때문에 현재 개판인 파일 넘버들을 정리합니다.
티스토리 코드 가독성 때문에 먼저 코드 파일을 공유합니다. (주석도 잘 달아놓음)
코랩으로 열기를 권장합니다.
https://github.com/inhovation97/personal_project/tree/main/pytorch
inhovation97/personal_project
개인 프로젝트. Contribute to inhovation97/personal_project development by creating an account on GitHub.
github.com
<1. 이미지 넘버링 (파일 이름 변경)>
최종적으로 resnet을 모델링해야하기 때문에 gpu가 없어서 코랩을 이용합니다.
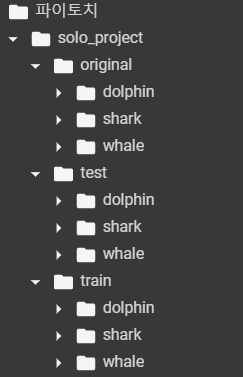
미리 train/test 폴더와 라벨 마다의 폴더들을 만들어줍니다.
현재 이미지들은 original 폴더에만 라벨에 따라 분류되어 있습니다.
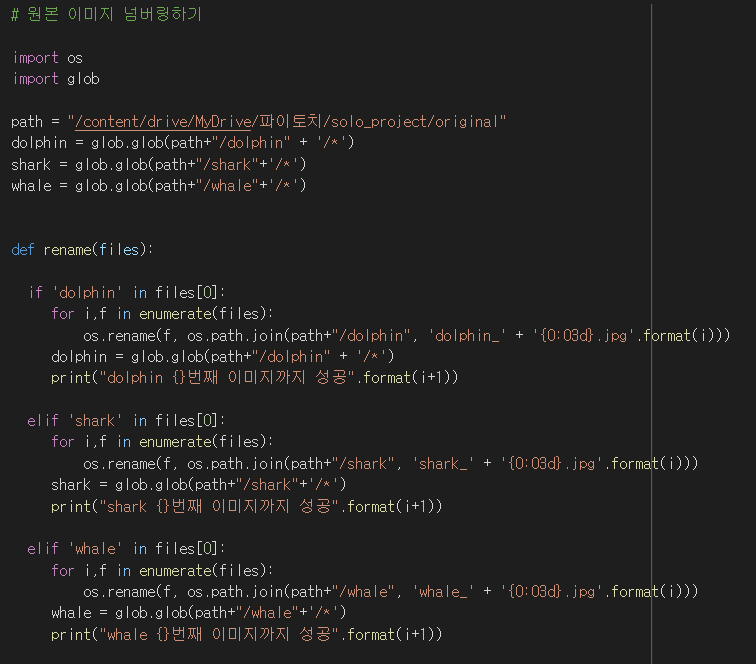

os와 glob 모듈을 이용해 rename 함수를 만들어줍니다.
함수를 실행하면 이렇게 뜹니다.
이제 각각 폴더의 내부 이미지의 이름들을 보면 '000~끝번호'로 넘버링이 잘 정렬되었을 겁니다.
근데 이 함수를 2번 이상 돌리면, 갑자기 이미지들이 뒤죽박죽 쓰레기통으로 가버리더군요(???)
아마 서버 문제인가 싶어요.
저와 같이 코랩 환경이라면 꼭 1번만 돌리세요!
안그러면 휴지통 이미지 복구하고 다시 코드를 돌려야됩니다;;

제가 가장 걱정했던 부분입니다.
크롤링 후에 이미지를 수동으로 정제했기때문에 data가 imbalance될 가능성이 컸기때문입니다.
근데 이 정도 비율이면 크게 신경쓰지 않아도 될 정도로 밸런스가 괜찮은 것 같습니다!
다행입니다 ㅎㅎ
<2. 이미지 시각화하기 >
이제 넘버링도 잘 정렬되었으니 크롤링했던 이미지들을 한 번 시각화 해봅시다.
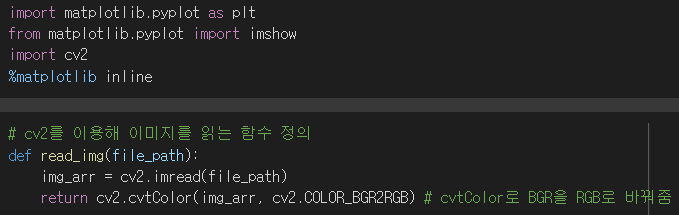
시각화를 위해서는 cv2 모듈을 이용해 이미지를 읽어줍니다.
이때 이미지를 BGR에서 RGB로 바꿔줍니다.
(과거 BGR이 표준이어서 여태까지 그렇게 이미지가 저장되어 왔다고하네요.)


먼저 각각 라벨마다 300개의 이미지 중 랜덤 추출하여 3개씩 9개의 이미지 array를 만들어줍니다.
이미지 array에서 추출한 랜덤의 이미지를 3x3의 figure 액자에 1,2,3열에 각각 dolphin, shark, whale의 이미지를 박아줄 겁니다.

시각화가 깔끔하게 잘 됐습니다! 이미지들도 제가 일일이 수작업으로 정제했기 때문에 이상한 이미지들이 없습니다.
문제점은 이미지 size들이 전부 다르다는겁니다.
다음 포스팅에서 커스터마이징을 할 때에 resize를 해줄겁니다.
<3. 이미지 랜덤 추출하여 train/test split (파일 복사)>
이제 이미지들을 랜덤으로 train/test 파일에 split하여 파일을 복사해줘야합니다.
각 라벨마다 400장 정도되는 적은 양이기때문에 train/test를 8:2 비율로 저장할겁니다.

20% 비율인 test를 이용해 더 빠르게 split할 겁니다.
원래는 그냥 numpy형식으로 split하면 더 빠르겠지만, 직접 수집한 데이터이기 때문에 파일을 정리하기위해 폴더 자체를 정리하는겁니다.
math의 round 함수는 반올림해줍니다.

shutil 모듈을 이용해서 파일을 원하는 경로에 복사해주는 split 함수를 만들었습니다.
차집합을 이용하니 코드가 10줄도 안되네요.
<4. train/test의 이미지들을 다시 넘버링 >
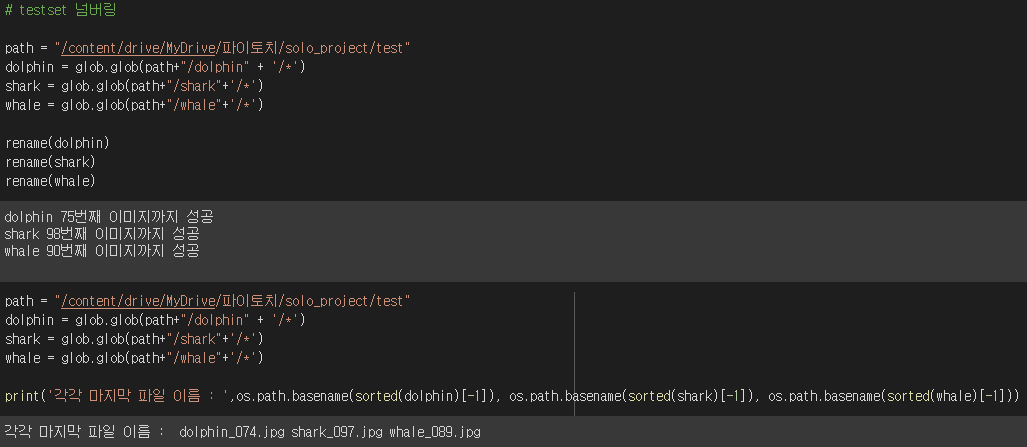
랜덤 추출하여 train/test를 split했기때문에 넘버가 다시 개판일겁니다.
따라서 다시 넘버링을 해줘야합니다.
위에서 미리 만들어 둔 rename함수를 다시 이용해서 train/test 폴더에 각각 다시 실행해주면 드디어 끝이납니다!
마지막 인덱스의 파일 이름이 각 라벨의 test 파일 비율과 일치합니다.
이렇게 데이터 수집/정리의 과정이 마무리가됩니다.
다음 포스팅은 이제 파이토치 프레임워크를 위한 데이터 커스터마이징입니다!
'Project > Image Classification Pipeline Project' 카테고리의 다른 글
| 5. Pytorch 텐서보드 활용 & image augmentation 중요성-실험 결과(이미지 수집부터 분류 모델까지) (0) | 2021.07.05 |
|---|---|
| 4. Pytroch resnet50 구현하기 (이미지 수집부터 분류 모델까지) (10) | 2021.07.02 |
| 3. (2) Pytorch 데이터 클래스 정의 & albumentations 활용하기(이미지 수집부터 분류 모델까지) (2) | 2021.06.18 |
| 3. (1) 이미지 전처리 - augmentation, normalization(이미지 수집부터 분류 모델까지) (1) | 2021.06.17 |
| 1. 파이썬 이미지 데이터 크롤링하기 (이미지 수집부터 분류 모델까지) (10) | 2021.05.23 |




댓글