SENet(논문 리뷰 링크)은 CNN모델에서 feature map에 집중한 attention 모듈이었다면, 각 픽셀 자리값 Spatial axes에 집중한 attention 모듈도 있을겁니다.
이번 포스팅은 그 둘을 모두 활용한 attention 모듈 CBAM: Convolutional Block Attention Module을 리뷰합니다.
(SENet보다 이 논문이 먼저라면, SENet을 먼저 공부하시는 것을 추천드립니다!)
저자가 한국분이셔서 저자가 직접 한국어로 작성하신 자료를 첨부합니다. 저자분이 이미 CBAM전에 BAM이라는 논문으로 연구를 하셨는데, 성능을 개선한 후속연구인 CBAM만 다루겠습니다. 논문 코드 링크
한글 자료가 있길래 아싸 꽁짜 논문 싶었는데 역시 원 논문과 코드를 살펴야했습니다...
Abstract는 자세히 짚고, 나머지는 중요한 부분들 위주와 저의 생각들로 포스팅합니다.
1. Abstract
2. CBAM 구조 & 동작 원리
- Channel Attention Module
- Spatial Attention Module
3. 아키텍쳐 실험
Abstract
단순하면서도 효과적인 Convolutional Block 어텐션 모듈을 소개합니다.
이 모듈은 feature map이 주어지면 2가지 과정이 분리되어 각각 순차적으로 진행되는데, channel attention, spatial attention map을 생성하여 이를 원래의 input feature map에 곱해줌으로써 adaptive feture refinment의 효과를 냅니다.
CBAM은 light하면서도 general한 모듈이기 때문에 어떤 CNN아키텍쳐에도 자유롭게 부착할 수 있고, 모델 전체를 end to end로 학습이 가능합니다. (활용도가 높다.)
ImageNet-1K, VOC 2007detection 데이터로 많은 연구를 통해 CBAM을 검증했습니다.
다양한 모델에서 classification이나 detection에서 성능 향상이 있었으며, 광범위하게 활용할 수 있다는 것도 확인했습니다.
CBAM 구조 & 동작 원리

CBAM은 BAM모듈의 후속 연구로 attention모듈의 성능을 극대화시켰습니다.
먼저 SENet처럼 channel간의 관계를 살펴 어떤 채널에 더 집중할 지 인코딩한 다음( Channel attention -> F` ),
전체 채널 내의 픽셀 별로는 어디에 더 집중할지 인코딩하여( Spatial attention -> F`` )
최종적으로 이를 원래의 input feature map에 더해줍니다. ( ResBlock을 적용한 것. )
2개의 attention 과정에 대해 각각 더 자세히 살펴 봅시다.
Channel Attention Module


Focus on 'WHAT'
Channel Attention Module은 SENet과는 Squeeze 과정이 조금 다릅니다.
원래는 이전 Conv block에서 받아온 Feature map들에 대해 Global AVG Pooling을 통해 1x1xC의 벡터들로 인코딩하지만 CBAM은 그림과 같이 MaxPooling도 진행하여 값을 가져옵니다.
논문에서는 max pooling에서 또 다른 중요한 단서들을 얻을 수 있다고 합니다.
( max pooling도 avg pooling처럼 글로벌하게 풀링을 해줍니다. )
따라서 max와 avg 풀링으로 인코딩된 2개의 벡터들을 각각 MLP 하여 비선형성을 한 번 가해줍니다.
MLP는 중간에 hiddenlayer를 통해 c/r만큼 수축시키는데, 본 연구에서 최적의 값으로 r=16을 찾았다고 하네요.
( 이 과정은 SENet의 Excitation 과정과 같습니다. )
이 때 둘은 같은 Channel로 부터 나온 벡터들이기 때문에 동일한 MLP를 거쳐, 더해진 뒤 최종 sigmoid로 확률화된 값으로 최종 인코딩됩니다.
Mc(1x1xC)가 출력
Mc는 input feature map( HxWxC )으로 부터 생성된 값으로, 서로 다른 C개의 feature map들간의 사이를 고려하여, 어떤 feature map이 중요한지 확률로 표현된 값들입니다.
이 값을 이제 input feature map F에 곱해주어 F`를 생성하게 됩니다.

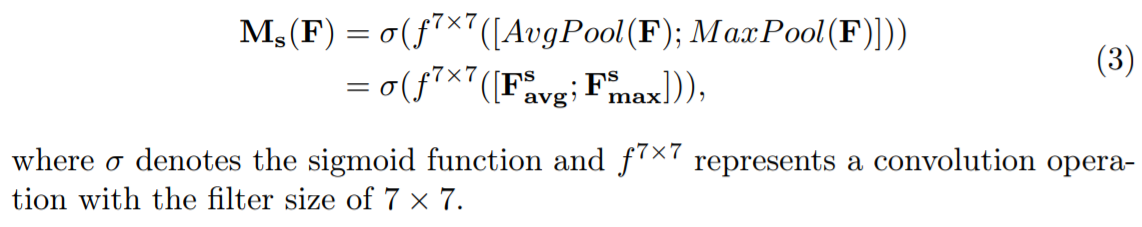
Focus on 'WHERE'
어떤 채널에 집중할지 Channel Attention을 적용한 F`를 얻었으니 F`로부터 Spatial Attention을 순차적으로 진행합니다.
이 과정에서는 CxH개의 픽셀중 어느 부위에 집중할지를 인코딩하는 단계입니다.
(그래서 최종 Ms를 보면 HxWx1 사이즈인 것입니다.)
논문을 따르면, 이 과정은 SENet에서는 없던 attention기법으로 Channel attention과는 상호보완적인 기능을 해줍니다.
먼저 채널축으로 AVG pooling & MaxPooling을 각각 진행한 뒤, concatenate하여 HxWx2를 만들어냅니다.
feature map이 2-channel이므로, Spatial attention을 위해 7x7 Conv를 진행하여 HxWx1로 만들어줍니다.
위 과정을 거치면 최종적으로 Spatial attention map(HxWx1)인 Ms가 생성됩니다.
해당 모듈은 어떤 CNN아키텍쳐에도 자연스럽게 적용이 가능합니다.
아키텍쳐 실험

Channel attention 과정에서 고려했던 아키텍쳐에 대해 실험을 했습니다.
Squeeze과정에서 풀링 방식을 두고 실험한 결과인데,
둘 다 쓰는 것이 좋아 채택하게 되었네요.

spatial attention 아키텍쳐 부분 실험입니다.
우선 저는 Spatial attention이라길래 당연히 1x1으로 channel reduction을 생각했었는데, 이 부분에서도 avg & max Channel Pooling을 적용하는 것은 생각 못 했습니다.
왜 7x7ConV로 인코딩한지 궁금했는데, 3x3Conv와 비교실험하여 더 좋은 것을 채택했네요.
논문에서는 broad view가 중요한 region을 결정하는 데에 더 도움이 된 것 같다고 합니다.
( 사실 BAM 논문에서는 artous ConV를 이용했는데, 왜 바꾸었는지 이유는 없네요. 개인적으로 그 부분 짚어줬으면 좋았을 것 같습니다. 아마 연산할 양이 많지 않아 굳이 이 부분에서 1x1이나 3x3 혹은 artous로 파라미터를 아낄 이유는 없다고 생각되긴 하네요. )

선행 연구였던 BAM은 아키텍쳐도 약간 차이는 있지만 가장 큰 차이점은 두 attention module을 parallel하게 진행했었지만, Channel -> spatial 순서로 sequential하게 진행한 CBAM의 성능이 더욱 좋았다고 합니다.

이미지넷 챌린지 분류 성능을 비교한 것인데,
CBAM의 성능이 SENet보다 뛰어나게 나온 것을 알 수 있습니다.
학습 파라미터도 거의 차이가 안나기 때문에 확실히 더 좋은 attention 모듈로 볼 수 있겠네요.
요즘도 많이 쓰이는 지는 잘 모르겠습니다...

GradCAM을 이용해서 각 네트워크가 예측한 타겟 물체의 위치 (object extent)를 시각화 하였습니다. Baseline + CBAM > Baseline + SE > Baseline 순으로 정성적인 결과가 더 좋게 보입니다. 곧 업데이트 될 컨퍼런스 버전에는 GradCAM결과를 이용한 user study 실험이 추가되었습니다. 이를 통해 CBAM의 interpretability (object extent)가 더 좋음을 정량적으로 보였습니다.
https://blog.lunit.io/2018/08/30/bam-and-cbam-self-attention-modules-for-cnn/
'논문 리뷰 > Classification' 카테고리의 다른 글
| [논문 리뷰] SENet 설명 (Squeeze-and-Excitation Networks)(2018) (2) | 2022.02.07 |
|---|---|
| [논문 리뷰] DenseNet(2017) 설명 (0) | 2022.02.05 |
| [논문 리뷰] ResNet(2015) 설명 (0) | 2022.01.19 |
| [논문 리뷰] GoogLeNet(2014) 설명 (2) | 2021.10.03 |
| [논문 리뷰] VGGnet(2014) 설명 (0) | 2021.09.08 |



댓글